Från datakaos till klarhet: Att omvandla företag med Data Fabric
Från datakaos till klarhet:
Att omvandla företag med Data Fabric

(Källa: IBM)
Publicerad: 20.03.2024
I dagens digitala era står företag inför den enorma utmaningen att hantera ett ständigt växande universum av data. Kundinteraktioner, operativa data, IoT–enheter och mycket mer bidrar till en stor volym och variation av data, vilket kan överväldiga traditionella datahanteringssystem. Data Fabric erbjuder en innovativ teknisk lösning som inte bara hanterar, utan även intelligent sammanflätar data från olika plattformar och miljöer. Denna artikel utforskar Data Fabric, dess kritiska komponenter och varför det är avgörande för företag som eftersträvar flexibilitet och konkurrensfördelar.
Vad är Data Fabric?
Data Fabric är mer än bara en teknisk komponent; det är en arkitektur och en uppsättning datatjänster som erbjuder konsekventa funktioner över ett spektrum av slutpunkter, från lokala till molnbaserade miljöer. Genom att integrera AI, datahantering, datastyrning, dataintegration och dataanvändning säkerställer det sömlös datatillgänglighet och kvalitet, inkluderande både nuvarande och framtida datalagerinvesteringar.
Tekniken möjliggör realtidsdataåtkomst utan att kompromissa med säkerhet eller efterlevnad, vilket är avgörande för att effektivisera affärsprocesser. Ett enkelt sätt att förstå detta är att följa AI-stegen, som innebär att samla in, organisera, analysera och använda all företagsdata för att förbättra kundupplevelser samt utveckla bättre tjänster och produkter.

(Källa: IBM)
Varför Data fabric är så viktigt
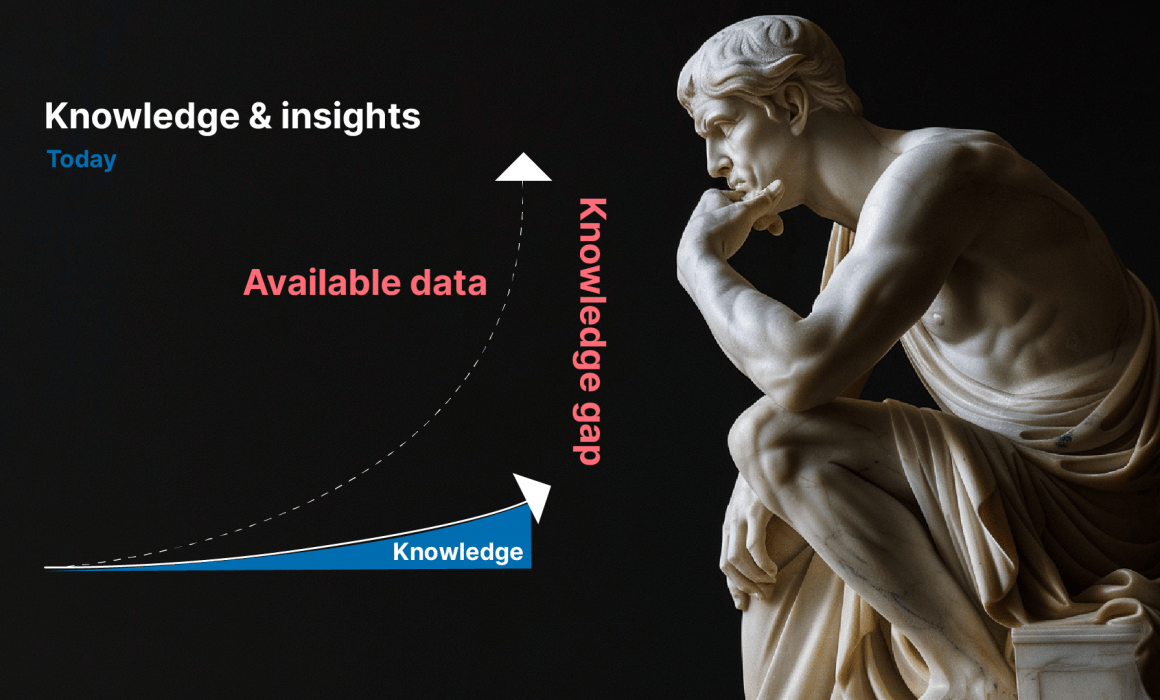
Vi är på väg in i en ny teknikera där huvudutmaningen blir att överbrygga klyftan mellan tillgänglig data och den information som faktiskt omvandlas till kunskap och insikter. Till skillnad från tidigare teknologiska framsteg kräver kunskapseran användning av avancerade analytiska verktyg och metoder för att bearbeta och tolka stora mängder data från många olika källor.
Dessa verktyg måste inte bara hantera stora datamängder utan också anpassas för att extrahera meningsfulla insikter, hantera datas komplexitet samt navigera de etiska, integritets- och säkerhetsutmaningar som datanvändningen medför. För att möta dessa unika utmaningar krävs en kombination av teknisk innovation och tvärvetenskapligt samarbete samt en uppgradering av arbetskraftens kunskaper.

(Källa: IBM)
Som ni ser finns det mycket att vinna på att överbrygga klyftan, men teknik, plus skala, plus människor är lika med komplexitet. Det är där vi befinner oss idag och det är därför det finns så få företag som kan överbrygga det gapet.
Hur kan en Data Fabric hjälpa till?
Data Fabric hanterar dessa utmaningar genom att tillhandahålla:
1. Universell tillgång till data: Underlättar enkel åtkomst till data från olika källor och miljöer, vilket är avgörande för en framgångsrik multi-cloud-strategi.
2. Helhetssyn: Förenkla processerna för datahantering, från insamling till användning, och därigenom påskynda datans livscykel.
3. Styrning och efterlevnad: Säkerställa att data nås och används på rätt sätt i hela organisationen genom verkställbara policyer.
Sammanfattningsvis syftar Data Fabric till att överbrygga klyftan mellan ett överflöd av data och de insikter som kan erhållas från den. Genom att kombinera teknik och mänsklig expertis omvandlas rådata till en strategisk tillgång som driver kundengagemang, produktinnovation och operativ effektivitet. I en tid där data är överflödande men insikter är av yttersta värde, är Data Fabric inte bara fördelaktigt, det är avgörande för företag som strävar efter framgång i det informationsdrivna landskapet.
Arkitektur för Data Fabric: En närmare titt
Data Fabric skapar en distribuerad datamiljö som integrerar data från olika operativa källor för BI, analys och datavetenskap. Denna integration möjliggörs genom kontinuerlig analys av metadata, stödd av moderna processer som aktiv metadatahantering, semantiska kunskapsgrafer och inbäddad maskininlärning.
Utmärkande faktorer för Data Fabric:
– Förstärkt datakatalog: Analyserar alla typer av metadata för att skapa sammanhang.
– Kunskapsgraf: Illustrerar relationer mellan dataenheter, förstärkt med enhetlig datasemantik.
– Aktivering av metadata: Övergår från manuell till automatisk hantering av metadata, med hjälp av maskininlärning för skalbarhet.
– Rekommendationsmotor: AI/ML-algoritmer analyserar, lär sig och gör förutsägelser om dataekosystemet.
– Förberedelse och inmatning av data: Stödjer alla vanliga metoder för dataförberedelse och leverans.
– DataOps: Slår samman DevOps med datateknik och datavetenskap och tillgodoser både IT- och affärsbehov.
Implementering av Data Fabric
För att implementera en Data Fabric-arkitektur krävs en blandning av lösningar, med betoning på ett enhetligt datatjänstlager som prioriterar datakvalitet och styrning. Gartner beskriver fyra pelare för implementering:
– Samla in och analysera metadata: Omfamna alla metadatatyper för en heltäckande förståelse. Och mappning till underliggande datamodeller.
– Aktivera metadata: Omvandla passiva till aktiva metadata för dynamisk hantering.
– Kurera kunskapsgrafer: Berika data med semantik för att förbättra tolkningen.
– Robust grund för dataintegration: Etablera en stark bas för insamling, hantering, lagring och åtkomst av data.
Data Fabric vs. traditionell datahantering
Data Fabric utmärker sig genom att erbjuda realtidsåtkomst till data utan behovet av att flytta dem, vilket främjar en komponerbar design och accelererar utvecklingsprocesser. Det demokratiserar dataåtkomst, löser problem med datasilos, och förbättrar säkerhet, efterlevnad och styrning. Detta skiljer sig från koncept som datasjöar, som mer fokuserar på insamling än anslutning.
Utmaningar med Data Fabric
En av de största utmaningarna med Data Fabric är att hantera felaktiga eller duplicerade data i källsystemen, vilket kan äventyra dataintegriteten och leda till riskabelt beslutsfattande. För att motverka detta kan organisationer implementera robust datastyrning vid källan och använda avancerade verktyg för dataförberedelse för att korrigera fel och dupliceringar. Kontinuerlig övervakning och validering av data är också avgörande.
En annan utmaning är problem med API-data, såsom data som saknas eller blir otillgängliga på grund av dåliga lagringsrutiner. För att övervinna dessa hinder krävs tydliga standarder för data- och API-hantering som säkerställer datakvalitet och tillgänglighet. Middleware-lösningar eller datavirtualisering kan underlätta åtkomsten till dåligt lagrade data, medan samarbete med dataleverantörer kan förbättra API-funktionaliteten.
Att hantera dessa utmaningar förbättrar inte bara funktionaliteten och tillförlitligheten hos Data Fabric-implementeringar utan säkerställer också att organisationer kan dra nytta av integrerade datalandskap för välgrundat beslutsfattande och innovation.
Slutsats
Data Fabric står inte bara som ett tekniskt framsteg utan också som ett viktigt ramverk för företag som navigerar i den komplexa datahanteringen av idag. Genom att integrera olika datakällor, förbättra styrningen och möjliggöra insikter i realtid, positionerar sig Data Fabric som en nyckelfaktor för flexibilitet och innovation. Med fokus på anslutning, intelligens och tillgänglighet, representerar det ett paradigmskifte mot ett mer informerat och effektivt utnyttjande av data. Eftersom företag strävar efter att överbrygga klyftan mellan ett överflöd av data och handlingsbara insikter, blir adoptionen av Data Fabric inte bara fördelaktig, utan avgörande för framgång i det informationsdrivna landskapet.
Vill du veta mer? – Hör av dig till oss!


